PythonAnywhereAnywhere
We recently added something cool to PythonAnywhere, our Python online IDE and web hosting environment -- if you're writing a tutorial, or anything else where you'd find a Python console useful in a web page, you can use one of ours! Check it out:
What's particularly cool about these consoles (apart from the fact that they advertise the world's best Python IDE-in-a-browser) is that they keep the session data on a per-client basis -- so, if you put one on multiple pages of your tutorial, the user's previous state is kept as they navigate from page to page! The downside (or is it an upside?) is that this state is also kept from site to site, so if they go from your page to someone else's, they'll have the state they had when they were trying out yours.
Bug or feature? Let me know what you think in the comments...
Busy, busy, busy
A couple of weeks back we were brainstorming about other ways we could make use of the code infrastructure we'd put together for Dirigible. We had loads of stuff for running functional tests, determining dependencies between spreadsheet cells, executing untrusted user code safely on our servers, and so on. Any of those could potentially make an interesting product, so we put together some basic landing pages, one for each idea, and put a bit of money into Google AdWords to see if any of them got any interest.
One of them took off immediately, and even started getting traction on Twitter: PythonAnywhere, an online Python IDE and web application environment -- basically, Dirigible without the spreadsheet grid. This fits in with what we suspected -- lots of people were interested in Dirigible, but it wasn't the spreadsheet side of it that excited them, it was the easy Python grid computing.
What's been particularly cool with this idea is not only that most of it is done and "just" needs breaking out of Dirigible and putting into a new product, but that people are keen to engage with us about it. When people signed up on our landing page, we sent them an email with a few questions -- "What would you use it for? Which features excite you? What would you pay for it? Any suggestions for other features?" About 25% of people have replied, with lots of great feedback, and we've changed our plans (and altered the relative priorities of features) based on their input. All very Lean Startup...
Anyway, all good clean fun. If you'd like a look at it when it goes into beta, you can sign up on the site, or just leave a comment below.
London Financial User Group Meeting: 17 January
The next meeting of the LFPUG will be on 17 January, from 19:00 – 21:00 — location TBD. Two talks are scheduled:
- Developing and Deploying Python applications on GPU Cloud Platforms, Suleiman Shehu, CEO of Azinta Systems
- Black-box model validation with Python, Patrick Henaff
Both sound interesting, the first in particular! There's still time to propose a lightning talk, too — I think the best way is to send the organiser, Didrik Pinte, an email. If you're on LinkedIn, there's also more information in the LFPUG group there.
A big announcement from Resolver
So, I've let various hints drop over the last few months, but we did the official annoucement today: a new product from Resolver, called Dirigible (thanks to Wikipedia's "Random page" link :-). It's been in private beta for a few weeks, and we decided it was time to get the news out there about it. As to what it is... our tagline is that it is "a spreadsheet-like tool for Python grid computing". That's kind of fuzzy (and probably needs a bit of work), but what I do want to make clear is what it's not: it is not just a web-based version of Resolver One, our desktop Python spreadsheet.
Instead, it's something much more developer-focused, built from the ground up -- sharing code with Resolver One, of course, but not trying to duplicate it. To quote the official annoucement:
We took the things from Resolver One that made software developers say "wow" -- like Python-based formulae, objects in the grid, and the ability to treat a spreadsheet as a function and call it from another sheet. Then we worked out what we could make better by coding just those things as a web application backed by traditional Python -- not IronPython -- on a grid of Linux servers.
You can read more about Dirigible and how it relates to Resolver One on the company blog, or there's a more concise version on the product's own web page. If you'd like to try it out, there's a signup form on the main Dirigible page; we're keeping beta user numbers small for now, but building up as we gain confidence that we've not done anything totally stupid with regard to security or scalabity...
I think everyone at Resolver's done a great job in putting it all together -- of course, being able to share code with Resolver One helped a lot :-) And I'm sure that Dirigible's going to be a great addition to the company's product line.
London Financial User Group Meeting: September 15
The next meeting of the LFPUG will be on September 15, from 19:00 - 21:00 -- location TBD. Didrik Pinte will be talking about Enthought's port of NumPy to .NET, which I'm very interested in hearing about.
More information on the LFPUG wiki page.
Generating political news using NLTK
It's election week here in the UK; on Thursday, we'll be going to the polls to choose our next government. At Resolver Systems, thanks to energy and inventiveness of our PR guys over at Chameleon, we've been doing a bunch of things related to this, including some analysis for the New Statesman that required us to index vast quantities of tweets and newspaper articles.
{kind=link}
Last week I was looking at the results of this indexing, and was reminded of the fun I had playing with NLTK back in February. NLTK is the Python Natural Language Toolkit; as you'd expect, it has a lot of clever stuff for parsing and interpreting text. More unexpectedly (at least for me), it has the ability to take some input text, analyse it, and then generate more text in the same style. Here's something based on the Book of Genesis:
In the selfsame day entered Noah , and asses , flocks , and Maachah . And Joseph said unto him , Abrah and he asses , and told all these things are against me . And Jacob told Rachel that he hearkened not unto you . And Sarah said , I had seen the face of the air ; for he hath broken my covenant between God and every thing that creepeth upon the man : And Eber lived after he begat Salah four hundred and thirty years , and took of every sort shalt thou be come thither .
It was the work of a moment to knock together some code that would read in all of the newspaper articles that we'd tagged as being about a particular subject, run them through a Beautiful Soup-based parser to pull out the article text, and feed that into NLTK, then to dump the results into a Wordpress blog (after a little manual polishing for readability).
Regular expressions and Resolver One column-level formulae
Recently at Resolver we've been doing a bit of analysis of the way people, parties and topics are mentioned on Twitter and in the traditional media in the run-up to the UK's next national election, on behalf of the New Statesman.
We've been collecting data, including millions of tweets and indexes to newspaper articles, in a MySQL database, using Django as an ORM-mapping tool -- sometime in the future I'll describe the system in a little more depth. However, from our perspective the most interesting thing about it is how we're doing the analysis -- in, of course, Resolver One.
Here's one little trick I've picked up; using regular expressions in column-level formulae as a way of parsing the output of MySQL queries.
Let's take a simple example. Imagine you have queried the database for the number of tweets per day about the Digital Economy Bill (or Act). It might look like this:
+------------+----------+
| Date | count(*) |
+------------+----------+
| 2010-03-30 | 99 |
| 2010-03-31 | 30 |
| 2010-04-01 | 19 |
| 2010-04-02 | 12 |
| 2010-04-03 | 2 |
| 2010-04-04 | 13 |
| 2010-04-05 | 30 |
| 2010-04-06 | 958 |
| 2010-04-07 | 1629 |
| 2010-04-08 | 1961 |
| 2010-04-09 | 4038 |
| 2010-04-10 | 2584 |
| 2010-04-11 | 1940 |
| 2010-04-12 | 3333 |
| 2010-04-13 | 2421 |
| 2010-04-14 | 1319 |
| 2010-04-15 | 1387 |
| 2010-04-16 | 3194 |
| 2010-04-17 | 860 |
| 2010-04-18 | 551 |
| 2010-04-19 | 859 |
| 2010-04-20 | 685 |
| 2010-04-21 | 528 |
| 2010-04-22 | 631 |
| 2010-04-23 | 591 |
| 2010-04-24 | 320 |
| 2010-04-25 | 363 |
| 2010-04-26 | 232 |
+------------+----------+
Now, imagine you want to get these numbers into Resolver One, and because it's a one-off job, you don't want to go to all the hassle of getting an ODBC connection working all the way to the DB server. So, first step: copy from your PuTTY window, and second step, paste it into Resolver One:
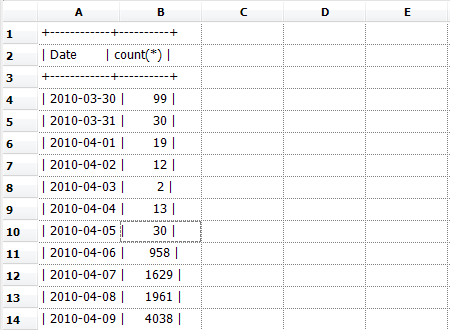
Right. Now, the top three rows are obviously useless, so let's get rid of them:
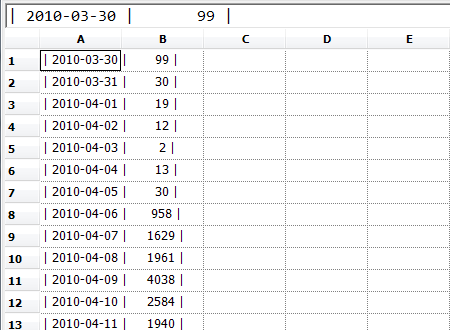
Now we need to pick apart things like | 2010-03-30 | 99 | and turn them into separate columns. The first step is to import the Python regular expression library:

...and the next, to use it in a column-level formula in column B:

Now that we've parsed the data, we can use it in further column-level formulae to get the dates:
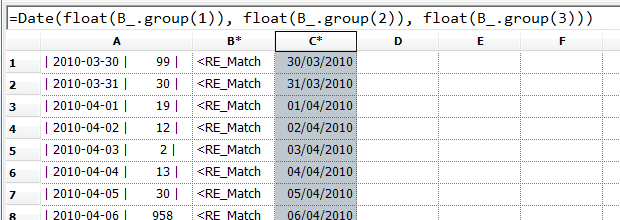
...and the numbers:
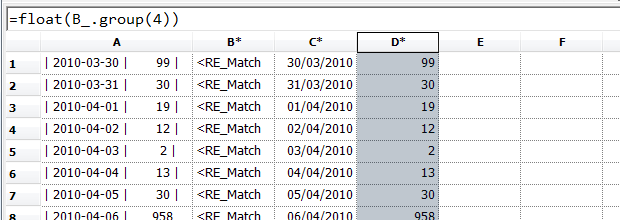
Finally, let's pick out the top 5 dates for tweets on this subject; we create a list
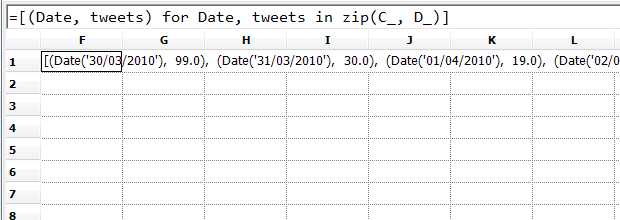
...sort it by the number of tweets in each day...
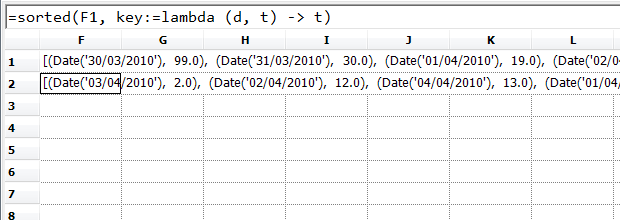
...reverse it to get the ones with the largest numbers of tweets...
...and then use the "Unpack" command (control-shift-enter) to put the first five elements into separate cells.
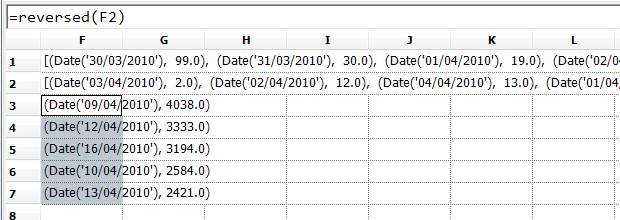
Now, once we've done this once, it's easy to use for other data; for example, we might want to find the fives days when Nick Clegg was mentioned most on Twitter. We just copy the same kind of numbers from MySQL, paste them into column A, and the list will automatically update:
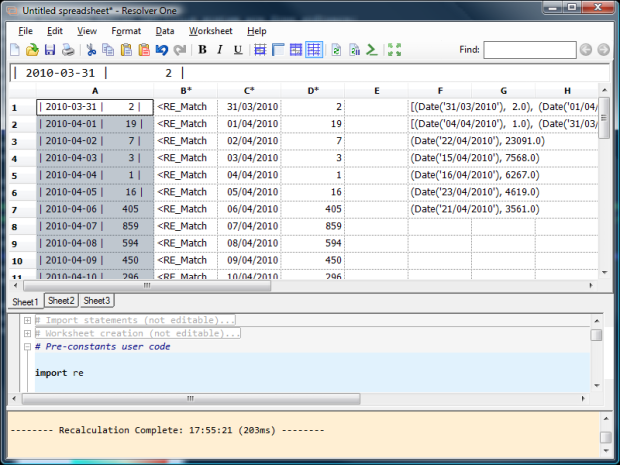
So, a nice simple technique to create a reusable spreadsheet that parses tabular data.
OpenCL: .NET, C# and Resolver One integration -- the very beginnings
Today I wrote the code required to call part of the OpenCL API from Resolver One; just one function so far, and all it does is get some information about your hardware setup, but it was great to get it working. There are already .NET bindings for OpenCL, but I felt that it was worthwhile reinventing the wheel -- largely as a way of making sure I understood every spoke, but also because I wanted the simplest possible API, with no extra code to make it more .NETty. It should also work as an example of how you can integrate a C library into a .NET/IronPython application like Resolver One.
I'll be documenting the whole thing when it's a bit more finished, but if you want to try out the work in progress, and are willing to build the interop code, here's how:
- Make sure you have OpenCL installed -- here's the NVIDA OpenCL download page, and here's the OpenCL page for ATI. I've only tested this with NVIDIA so far, so I'm keen to hear of any incompatibilities.
- Clone the dot-net-opencl project from Resolver Systems' GitHub account.
- Load up the
DotNetOpenCL.slnproject file in the root of the project using Visual C# 2008 (here's the free "Express" version if you don't have it already). - Build the project
- To try it out from IronPython, run
ipy test_clGetPlatformIDs.py - To try it in Resolver One, load
test_clGetPlatformIDs.rsl
That should be it! If you want to look at the code, the only important bit is in
DotNetOpenCL.cs -- and it's simply an external method definition... the tricky
bit was in working out which OpenCL function to write an external definition for,
and what that definition should look like.
I've put a slightly tidied version of the notes I kept as I implemented this below, for posterity's sake; if you're interested in finding out how the implementation went, read on...
Playing with NLTK
I spent some time this afternoon playing with NLTK, the
Python Natural Language Toolkit; the book
is highly recommended. I couldn't resist sharing the results of the first time I
tried its generate function, which takes a particular text and tries to automatically
generate more text in the same style.
First, from the Book of Genesis:
In the selfsame day entered Noah , and asses , flocks , and Maachah . And Joseph said unto him , Abrah and he asses , and told all these things are against me . And Jacob told Rachel that he hearkened not unto you . And Sarah said , I had seen the face of the air ; for he hath broken my covenant between God and every thing that creepeth upon the man : And Eber lived after he begat Salah four hundred and thirty years , and took of every sort shalt thou be come thither .
Next, Jane Austen:
[ Sense and Sensibility by Jane Austen 1811 ] CHAPTER 1 The family of his relations , I know Marianne ' s indisposition , beyond giving time for the world to seeing YOU .-- Very far from being weary of her feeling how more than commonly joyful . He was four years . Every thing was disregarded . I had called in Berkeley Street , January . " Mrs . Jennings , sagaciously smiling , " For my part , not being Willoughby , where much of his fate with Miss Morton , with two pointers playing round him ,
And finally, from a corpus of IRC conversations:
now im lost i agree i saw the whole thing JOIN PART google 's start page .. lol yeah , he said this morning he is hoping they win tonight im gay ....... im happy as hell ...... jus aint #### lol U42 , how are you NICK : U23 what a combo hehehe JOIN . ACTION pictures the blues brothers behind that chicken wire screen . (((((((((( U34 ))))))))))))) Hi U7 ......... how are ya ll gotta watch my manners or she wo n't you play another somebody done somebody wrong song ? JOIN . ACTION wonders if U16
Scarily accurate :-)
London Financial Python Users' Group
I clearly need to post more stuff here so that it doesn't just turn into a blog announcing the LFPUG's meetings :-)
However, in the meantime, here are the details of the next one: it'll be on 11 March 2010, and is hosted this time by Man Investments Ltd at Sugar Quay, Lower Thames Street, London EC3R 6DU. As before, all are welcome, but for security reasons you need to register in advance; just drop an email to Didrik Pinte. (Update: old mailto link removed.)
Guest of honour this time around is Travis Oliphant, the creator of SciPy and the architect of NumPy. He'll be talking about NumPy memory maps and structured data-types, and Didrik will also give a talk about integrating C/C++ libraries using Cython. More suggestions for talks (or even better, offers to give talks!) are very welcome -- once again, just email Didrik, or post something in the LinkedIn group.